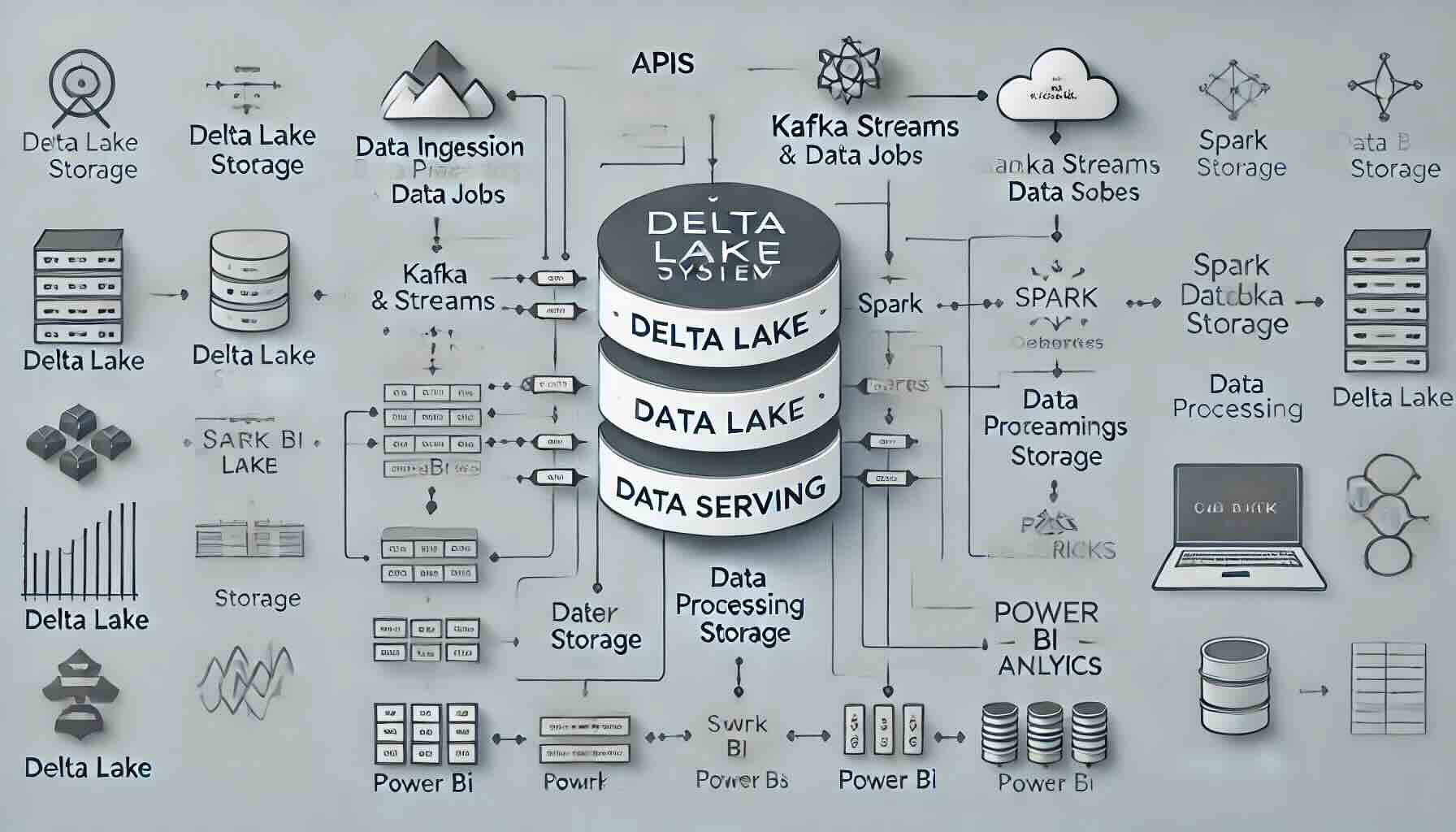
Medallion Architecture Data Pipeline
Welcome to our project showcase! Here’s a quick overview of how we use a medallion architecture for managing data streams.
Pipeline Highlights
- Data Ingestion with Kafka: Streaming data flows seamlessly from Kafka.
- Bronze Layer: Stores raw data as-is for historical tracking.
- Silver Layer: Data is cleansed and structured, ready for analytics.
- Gold Layer: Optimized Delta tables and fact tables for reporting and insights.
Gold Layer: KPI Classification Approach
In the gold layer, we implement a row-level KPI classification model. Instead of calculating KPIs for predefined hyper cubes or aggregated views, we:
Classify Each Item:
- Each row in the gold layer is checked against KPI definitions.
- A boolean column is added to indicate whether the item fulfills the KPI requirements (
true/false).
Dimension Filtering and Aggregation:
- The BI reporting tool allows users to select items dynamically using different dimensions (e.g., time, geography, or product type).
- KPIs are calculated using aggregation functions like
AVG()on the boolean values.
Master Data Integration:
- Dimensions for BI analysis, such as Product, Region, and Time, are sourced from the company’s master data system.
- These dimensions are integrated into the pipeline via a daily batch ETL process, adhering to SCD Type 2 for maintaining historical changes in dimension data.
Star and Snowflake Schemas:
- The overall structure of the data warehouse depends on the hierarchical complexity of dimensions:
- Star Schema: If dimensions have a flat hierarchy, they directly connect to the fact table, forming a star-like structure.
- Snowflake Schema: If dimensions contain multiple levels of hierarchy (e.g., Region → Country → City), they are further normalized into related dimension tables, forming a snowflake-like structure.
- The overall structure of the data warehouse depends on the hierarchical complexity of dimensions:
Benefits of This Approach:
- Flexible and scalable: Users can slice and dice data dynamically without predefined hyper cubes.
- Simplified pipeline: KPI logic is encapsulated at the item level, reducing complexity in ETL processes.
- BI-driven insights: KPIs are dynamically derived based on user queries and needs.
Comparison: Hyper Cubes in Classical Data Warehouses
What Are Hyper Cubes?
In classical data warehouses, hyper cubes are multidimensional structures used for organizing and analyzing data. They consist of:
- Dimensions: Perspectives for analysis, such as Time, Product, or Region.
- Measures: Numeric data or facts like sales or profit.
- Cells: Each cell contains a measure corresponding to a unique combination of dimensions.
For example:
| Product | Region | Time | Total Sales |
|---|---|---|---|
| Shoes | Europe | 2023 | $100,000 |
| Jackets | Asia | 2024 | $50,000 |
Hyper cubes are optimized for predefined aggregations and enable operations such as slicing, dicing, and drilling down.
Challenges of Hyper Cubes
- Predefined Structure:
- Dimensions and hierarchies must be predefined, limiting flexibility.
- Scalability Issues:
- Adding new dimensions increases storage and computational requirements exponentially.
- Static Aggregations:
- Pre-aggregated data cannot accommodate ad-hoc queries easily.
- ETL Complexity:
- Preparing hyper cubes requires extensive ETL processes for every possible combination of dimensions.
Modern Approach: Medallion Architecture with Delta Lake
In contrast to classical hyper cubes, our pipeline leverages a medallion architecture with Delta Lake. Key differences:
- Row-Level Processing: KPIs are not pre-aggregated but classified at the row level.
- Dynamic KPI Computation: Aggregations are deferred to the BI layer, enabling flexible queries.
- Scalable and Efficient: Delta Lake’s ACID compliance and scalability handle large volumes of data without the limitations of hyper cubes.
- Simplified ETL: Focuses on cleaning and structuring data rather than extensive pre-aggregation.
Why This Approach?
Our approach ensures:
- Flexibility for diverse queries and user-defined KPIs.
- Scalability to handle large-scale streaming data from Kafka.
- Simplified ETL pipelines, reducing processing time and complexity.
By integrating these advanced methods, we enable real-time insights, scalable analytics, and user-driven reporting capabilities.